In the field of data science, web crawlers are an important source of external data. However, under the circumstance that the existing anti-crawling mechanism is becoming more and more common and perfect, the simple violent crawler has become more and more unable to meet the actual data acquisition needs.
Specifically, one of the methods widely used in anti-crawling mechanisms is to check the IP address of the access request. If a large number of websites are accessed in a short period of time, the website’s server will trigger character verification or block the IP address.
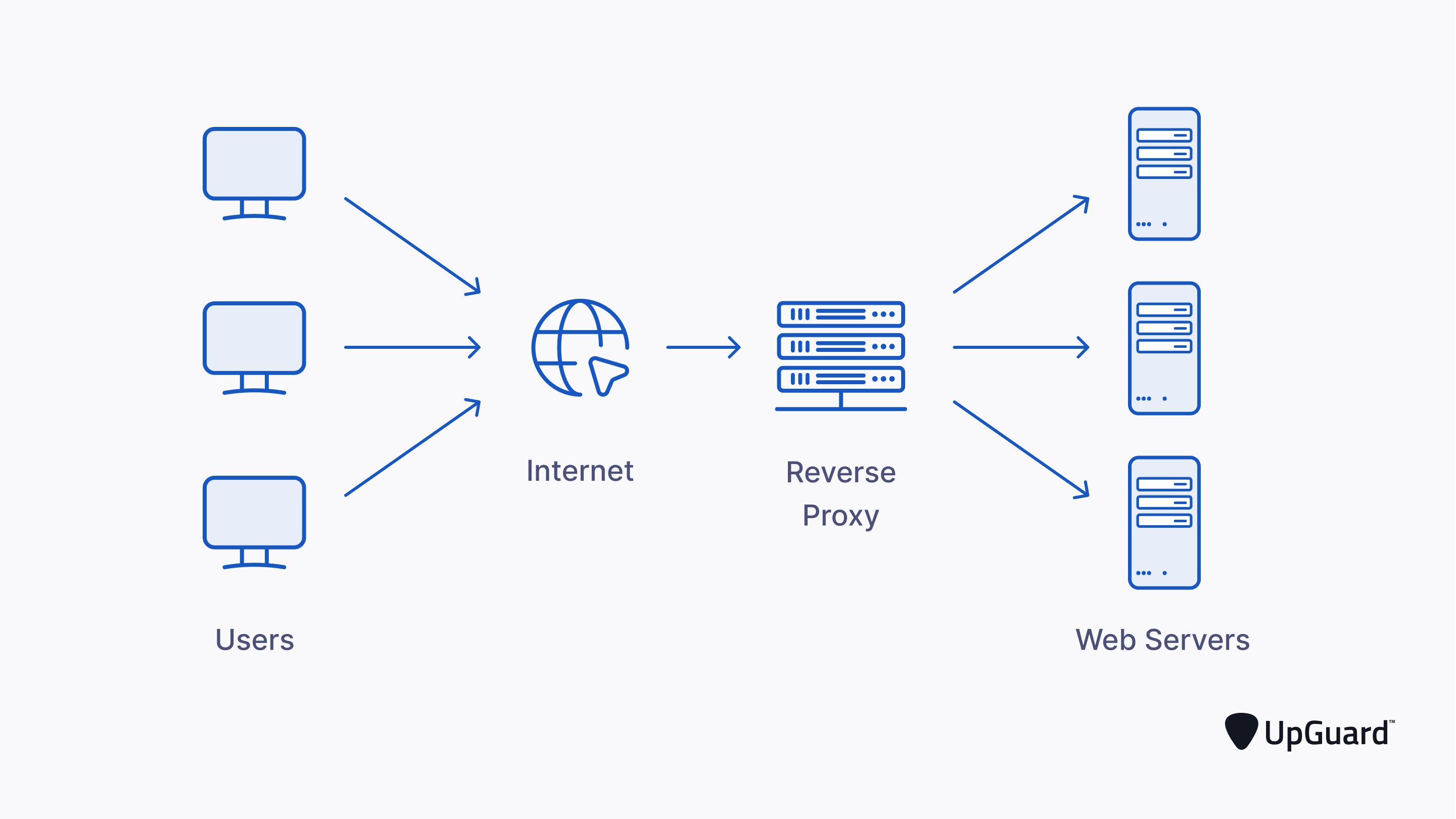
Therefore, in many cases, in order to avoid being blocked and blacklisted by the IP or manually entering the verification code, the crawler will use a proxy server to change the IP address.
The fundamental use of proxy servers is to hide a user’s IP or the IP of internal servers depending on your setup.
This is vital for network cybersecurity, as most cyberattacks need to gain access to specific target machines. Furthermore, cyberattackers might need to scalp credentials from a victim to escalate a fake user’s permissions.
In addition, you can also use proxy servers to create a demilitarized zone (DMZ) that enables any traffic to enter a no-trust segmented network zone. Through this setup, you can use proxies as a gateway to services and log traffic. By doing this, users need explicit, not implicit, trust to do anything in this zone.